이 글은 빅데이터 분석에 관심을 갖거나 시작하려는 분들에게 도움을 주는 글입니다.
최근 동향을 보면 빅데이터 분석을 쉽게해주는 도구로 파이썬, 판다스(pandas)가 대표적이다. 판다스는 파이썬(python)이라는 프로그래밍 언어로 만들어진 프레임워크다. 쉽게말해서 파이썬 문법으로 사용할 수 있는 도구의 집합체 정도로 요약해두면 된다. 그러니 판다스를 사용하려면 파이썬(python)을 기본으로 알고 있어야 한다.
그리고 판다스와 함께 numpy란 녀석도 곁가지로 꼭 알아두어야 한다. numpy는 C언어로 구현된 python 바인딩 수학(math) 패키지(프레임웍)다. 쉽게 말해서 numpy에서 제공하는 수학연산에 대한 구현이 c언어로 최적화 되어있어 매우 빠르다. 예를들어 데이터를 다루면서 벡터연산(한번에 여러데이터를 동시에 넘겨서 동시에 처리하는 것)이 매우 유용할 때가 있다. 구체적으로 for문으로 처리할 것을 numpy를 사용하면 데이터를 벡터연산으로 처리하여 성능이 향상된다. 특히 나중에 딥러닝을 할 때 GPU를 사용한 병렬처리에 이런 벡터화(vectorization)은 필수다.
뭐 이유야 어찌되었던 판다스와 numpy(넘파이)는 파이썬으로 빅데이터를 다루기위한 기본 중에 기본임을 부정할 수 없다.
어쩌면 최근 빅테이터 관련해서 파이썬(python)이 대세가 되는 이유가 이런 라이브러리들 때문이라 생각든다. 그전에 파이썬이라는 언어자체가 워낙 문법이 간결하여 이해하기 쉽기도하고 동적 타입 언어라 컴파일하지않고 실시간으로 인터프리터를 통해서 해석되기 때문에 데이터 분석을 위해서는 최적일 수 밖에 없다. 데이터를 시각화하여 실시간으로 데이터를 조작하면서 데이터의 분포나 통계량을 해석하는 데 있어서는 인터프리터 언어의 장점이 클 것이다.
물론 판다스의 단점도 있다. 판다스라는 도구는 매우 추상화된 도구라 간단한 함수로 정말 복잡한 기능을 수행할 수 있는 반면에 이런 추상화는 내부 자료형의 크기를 크게만들어 버린다. 데이터의 처리 속도와 매우 큰 데이터에 대해서는 무지막지한 메모리를 차지하게 된다. 이 문제는 실제로 실습하면서 크게 불편하지는 않을지 모르기 때문에 크게 언급하지는 않겠다. 만약 판다스를 사용할 때 자주 컴퓨터가 먹통이 된다면 대부분 메모리 문제일 것이다. 가장 간단한 해결책은 컴퓨터의 메모리를 늘리는 것이다. 메모리를 늘린다면 (최소 32GB 이상) 웬만한 데이터를 처리하는 데 문제가 없을 것이다. 이외에 또 다른 해결책(C언어를 바인딩하는 방법)도 있지만, 초심자라면 그렇다고만 알아두자. 그냥 메모리를 64GB~128GB까지 늘리자.
이제 데이터 분석을 위해서 당장 (아나콘다)anaconda를 설치하자.
https://thrillfighter.tistory.com/466
아나콘다는 파이썬+데이터분석 라이브러리+기타 머신러닝, 딥러닝 라이브러리 + 수학, 과학 관련 라이브러리 를 합쳐 놓은 것이다. 그냥 파이썬을 설치한다면 부수적인 판다스, numpy, 기타 머신러닝 라이브러리 들을 직접 설치해야 한다.
아나콘다를 권장하는 이유는 호환성 때문이다. 모든 라이브러리에는 버전이 존재한다. 그리고 라이브러리들 간에 호환성(버전에 따라서) 유무는 장담할 수 없다. 예를들어 파이썬 3.7에 판다스 최신버전을 설치했을 때 당장은 별 문제없이 동작하더라도 특정 상황에서 문제가 발생할 수 있고, 이런 문제점들이 리포트되면 개발자가 수정하여 재 배포하는 형식을 거치게 된다. 아나콘다는 이런 문제점들을 어느정도 처리하여 버전간에 호환성에 맞게 묶어서 배포하는 형식이므로 꼭 그렇게 하지 않을 이유가 없다면 아나콘다를 설치하는 것이 좋다.
아나콘다 최신버전(3.7)에서는 텐서플로우를 지원하지 않았는데 최근 나이틀리버전(nightly version)은 텐서플로우도 지원하게 된듯 하다. 어찌되었든 현 시점에선 아나콘다 3.5나 3.6이 데이터 분석, 딥러닝, 머신러닝에 가장 안정적이라 생각한다.
이렇게 설치를 했다면 ipython 또는 주피터 노트북을 사용하도록 한다.
ipython은 콘솔 화면이며 jupyter notebook은 웹 브라우저에서 좀 더 인터렉티브(interactive)한 데이터 분석을 할 수 있다. 시각화를 위해서는 주피터가 더 좋은 선택일 것이다.
다음은 주피터 노트북에서 판다스를 사용하는 아주 간단한 예제다.
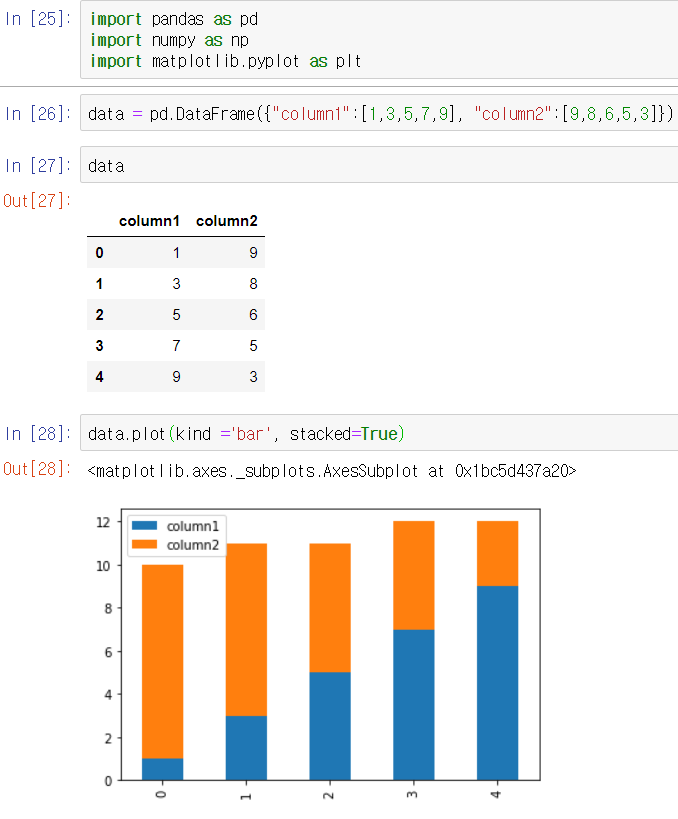
아주 기본적이 예제지만 판다스를 사용하는 이유를 충분히 보여준다.
위 그림을 보면 pandas와 numpy를 import 했다. 파이썬을 모르더라도 대략 어떤 의미인지는 알 수 있을 것이다. 이렇게 import 하므로써 해당 라이브러리를 사용할 수 있다. pandas에서 제공하는 데이터 프레임을 통해 위와 같은 데이터 테이블을 만들어 bar 차트로 시작화까지 했다. 이 작업을 하는데 1~2분정도면 충분하다. 어떤 데이터라도 데이터를 불러와서 시각화까지 위와 같은 작업량으로 가능하다. 물론 데이터를 정제하는 작업은 더 복잡하며 판다스를 익히려면 파이썬도 알아야 하므로 초심자에게는 여러 산들을 넘어야 하겠지만 충분히 배워둘 가치는 있다.