파이썬으로 쓰레드를 공부하다 보면 GIL(Global Interpreter Lock)에 대한 이야기가 심심치 않게 나온다. 공부를 하는 입장에서는 당장 GIL이 뭔지 몰라도 쓰레드를 만들고 프로그램을 돌리는데는 문제가 없다. 물론 공부를 하는 입장에서다.
파이썬이 발전되는 과정에서 하드웨어 역시 발전되어 왔다. 어는 순간 CPU는 클럭을 높이는 쪽에서 코어를 늘리는 쪽으로 발전의 방향이 변경되었다. 이런 변화는 프로그래밍 언어에도 큰 영향을 미쳤다. 왜냐면 1코어 시대에서는 CPU가 1개의 코어만 있는 게 당연했지만 현재는 다중 코어 CPU를 사용할 수 있도록 언어적인 차원에서 지원을 해야하기 때문이다.
그런데 파이썬(Cpython)은 GIL이라고 해서 인터프리터에 락을 거는 방식으로 다중 코어를 병행하여(동시실행) 사용하지 못하도록 했다.
그럼 왜 파이썬(Cpython)은 이런 선택을 한 것인지 간단히 알아보고 몇가지 실험과 의미를 되새겨 보도록 하겠다.
파이썬 인터프리터와 성능
파이썬은 인터프리터를 통해서 코드를 해석한다. 이말은 파이썬 코드가 실행되기 위해서는 파이썬 인터프리터라는 프로그램이 먼저 메모리에 로드되어야 한다는 뜻이다. 마치 자바언어의 JVM이 자바 바이트 코드를 번역해서 CPU에 넘겨주는 것과 비슷한 개념이다.
따라서 파이썬의 실행 속도는 매우 느리다. 객체역시 다른 언어와 등가의 데이터를 가진 객체라도 덩치가 훨씬 크다. 덩치가 클 수록 가지고 있는 정보는 많다. 따라서 간단해 보이는 객체를 사용해서 쉽게 많은 일들을 해결할 수 있다.
이런 방식으로 인해 파이썬은 성능이 낮은 스크립트 언어지만 진입장벽이 낮아 인기가 많다.
파이썬의 메모리 관리
이렇게 성능이 낮음에도 인기가 많은 파이썬은 객체의 생성과 소멸을 reference count를 통해서 관리한다.
refcount란 객체가 가지고 있는 속성으로 자신을 몇군데에서 참조하고 있는지에 대한 속성이다.
그리고 인터프리터는 refcount를 검사해서 해당 객체의 메모리는 회수할지를 결정한다.
파이썬에서는 이렇게 메모리 관리가 자동으로 되고 있다.
파이썬에 GIL이 있는 이유
사실 프로그래머의 입장에서는 GIL에 대해서 깊게 파헤칠 필요는 없고 핵심만 알면 된다. 나 역시 완전히 GIL의 깊은 속을 들여다 본 것이 아니고 문서에 나와있는 대로만 이해한 것 뿐이다. 그래서 한번 정리해본다.
우선 예를들어 보자.
파이선에서 A라는 스크립트를 실행하면 2개의 쓰레드가 생긴다고 해보자. 2개의 쓰레드를 1개의 코어 시스템에서 돌리면 동시에 돌아가는 것 처럼 보여도 사실은 cpu가 두 쓰레드를 번갈아 가면서 처리한다. 특정 시점에서는 언제나 CPU는 단 하나의 쓰레드만 처리하고 있다.
그런데 멀티코어 CPU라면 어떻게 될까? C와 같은 언어에서는 다중 코어라면 쓰레드가 여러 코어에서 동시에 돌아간다. 하지만 GIL 하에서는 코어가 몇 개든 상관없이 특정 시점에서 하나의 코어만 실행된다.
멀티코어 시대에 뒤쳐져 보인다 생각할 수 있겠다.
GIL은 이렇게 특정 시점에서 언제나 하나의 쓰레드만 실행하도록 만든 것이다. 다시 말해서 특정 시점에서 인터프리터를 사용하는 쓰레드는 언제나 1개라는 것이다. 이렇게 인터프리터(Interpreter)에 뮤텍스(mutex)락을 걸어서 GIL(Global interpreter Lock)이라는 이름이 붙여졌다.
그러면 파이썬은 왜 GIL을 채택했을 까?
다시 앞서 설명했던 내용을 정리해보면
1. 파이썬 코드는 인터프리터를 통해 실행된다.
2. 파이썬의 객체는 덩치가 크고 refcount를 통해서 메모리 관리가 이루어진다.
위 두가지 사실로 인터프리터는 객체에 참조가 생기가나 해제될 때마다 refcount를 +- (증감)하게 된다. 쓰레드 간에 공유하는 객체가 있다면 객체를 참조하는 연산(=)은 경쟁 상태(race condition)가되고 모든 객체에 대해서 참조가 증가 또는 감소될 때 lock을 걸어야 한다는 의미가 된다. 즉 모든 객체가 크리티컬 섹션이 된다.
정수 변수 하나까지 객체로 다루는 파이썬에서는 이렇게 객체마다 lock을 걸어야 하는 작업은 매우 비효율적 일 수 밖에 없다.
그래서 파이썬은 인터프리터를 락을 걸어버렸다. 쓰레드가 몇개건 CPU 코어에 관계없이 인터프리터를 사용하는 쓰레드는 오직 1개로 만들었다. 당연히 특정 객체에 대한 동시접근은 해결된다.
GIL의 의의
보통 프로그램이 하는 일은 CPU bound 작업(수학연산 등등) 이 아닌 한 대부분 I/O bound 작업을 하게 된다. 문서작업, 네트워크 작업(인터넷, 다운로등) 등등... CPU가 아닌 기타 장치가 처리하는 시간이 대부분이다.
쉽게 말해서 하나의 프로그램을 멀티 코어를 사용하는 형태로 만들 필요가 크게 필요없다는 것이다.
보통 멀티 코어를 요하는 프로그램은 특수한 경우다.
또한 multiprocessing 모듈을 통해서 멀티 프로세스 프로그래밍으로 여러 코어를 사용할 수도 있다. 또는 멀티 코어 쓰레딩을 위해 다른 프로그래밍 언어를 파이썬에 접합하던가 할 수도 있겠다.
파이썬은 파이썬 답게 사용하자
파이썬은 느리다는 것을 인정해야 한다.
파이썬으로 CPU를 많이 쓰는 작업을 쓰레드로 나누어 돌린 후 CPU 사용량을 살펴보면 특이한 것을 발견할 수 있다.
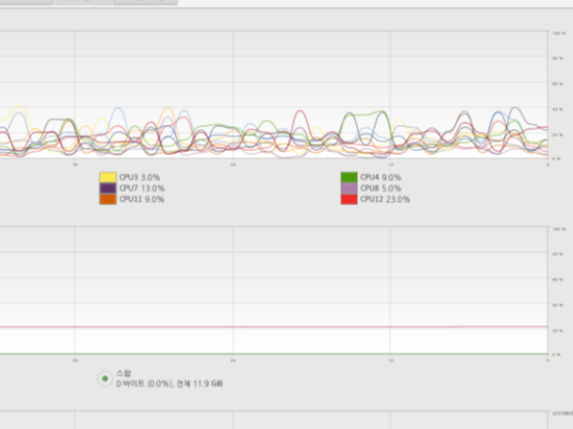
위 그림은 1부터 n 까지 더하는 작업을 10개의 쓰레드로 시킨 후 CPU의 사용량이다.
원래 아무 작업도 안했을 때 cpu 사용량은 5%도 채 안되었다. 위 그림은 40% 수준에서 여러 코어가 요동치면서 작업을 하고 있다. 그런데 코드에는 print나 다른 어떤 코드도 없이 덧셈 연산을 for문으로 돌렸음에도 cpu 사용률이 40%가 넘어가지 않음을 주목해야 한다.
또한 GIL에 의해서 한번에 하나의 코어의 사용량만 증가 감소해야할 텐데 동시에 여러 CPU가 약간씩 사용되는 것도 살펴보자.
쓰레드가 2개일 땐 55%까지 사용, 쓰레드 10개 CPU 사용율 약 40% 정도.
그리고 다음은 단 하나의 쓰레드로 똑같은 연산을 한 경우다.
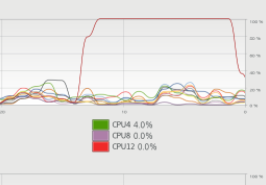
CPU 사용률이 100%다. 이게 정상이다.
다음은 C언어로 똑같은 작업(4개의 쓰레드)을 했을 때의 CPU 사용량이다.
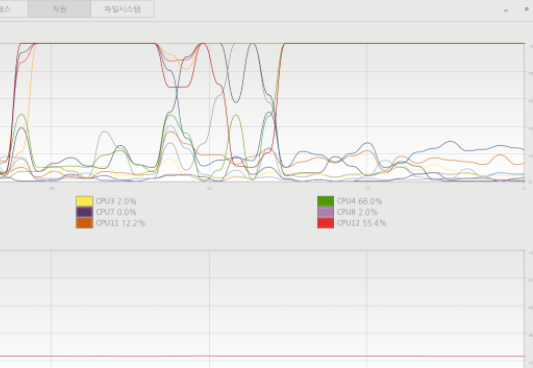
C 언어로 똑같은 작업이 약 100배이상 빨리 계산되어 각 쓰레드마다 원래작업을 100번 반복했다.
C로 만든 4개의 쓰레드 프로그램에선 4개의 코어가 계산에 동시에 참여함을 알 수 있다. 중간에 약간 요동치는 부분은 OS의 스케쥴러에 의한 것인 듯 하니 신경쓰지 말자.
결론을 내리면 파이썬의 멀티 쓰레드는 CPU 연산을 위한 것이 아니다. 안그래도 느린데 쓰레드 2개부터 CPU 사용량이 반으로 줄어버린다. 같은 CPU BOUND 이라도 2개의 쓰레드로 나누어서 했을 때 파이썬에서는 2배의 시간이 더걸린다는 뜻이 된다.
멀티 쓰레드를 사용할 때 내부적으로 어떤 처리를 하기 때문이라고 생각하는데 마치 CPU 사용률을 제한시킨 듯 보인다.
좀 더 실험을 하고 싶지만 다음에 더 파헤쳐 봐야겠다.